Task: A deep-learning head motion correction approach with cross-attention (DL-HMC++) to predict rigid head motion from one-second 3D PET raw data.
Rationale: Head movement poses a significant challenge in brain positron emission tomography (PET) imaging, resulting in image artifacts and tracer uptake quantification inaccuracies. Effective head motion estimation and correction are crucial for precise quantitative image analysis and accurate diagnosis of neurological disorders. To overcome this limitation, DL-HMC++ is porposed: a deep-learning head motion correction approach with cross-attention to predict rigid head motion from one-second 3D PET raw data. More specifically, DL-HMC++ introduces an enhanced model to overcome the limitations of the standard DL-HMC approach by incorporating a cross-attention mechanism, aiming to enhance motion estimation and generalization performance. This cross-attention mechanism takes a pair of features as input and computes their correlations to establish spatial correspondence between reference and moving 3D PET cloud images (PCIs). This explicitly enables the model to concentrate on the head region, which is the most relevant anatomy for motion estimation in brain PET studies.
Description: DL-HMC++ is trained in a supervised manner by leveraging existing dynamic PET scans with gold-standard motion measurements from external HMT. The deep learning approach to brain PET head motion correction estimates rigid motion at one-second time resolution. This data-driven motion estimation model utilizes one-second 3D PET cloud image (PCI) representations as input. The reference I_ref PCI and moving I_mov PCI are created by back-projecting the PET listmode data from one-second time windows at times t_ref and t_mov, respectively, along the line-of- response (LOR) with normalization for scanner sensitivity. For model training and evaluation, each one-second PCI has corresponding Vicra HMT information (rigid transformation matrix) as the gold-standard motion. The model is trained to estimate the rigid motion transformation θ = [t_x, t_y , t_z , r_x, r_y , r_z ] between I_ref and I_mov where θ includes three translation (t_d) and three rotation (r_d) parameters for each axis d = {x, y, z}. The network consists of three main components:
- the feature extractor;
- the cross-attention module; and,
- the regression layers.
The feature extractor employs a shared-weight convolutional encoder to capture regional features from both the reference and moving PCIs.
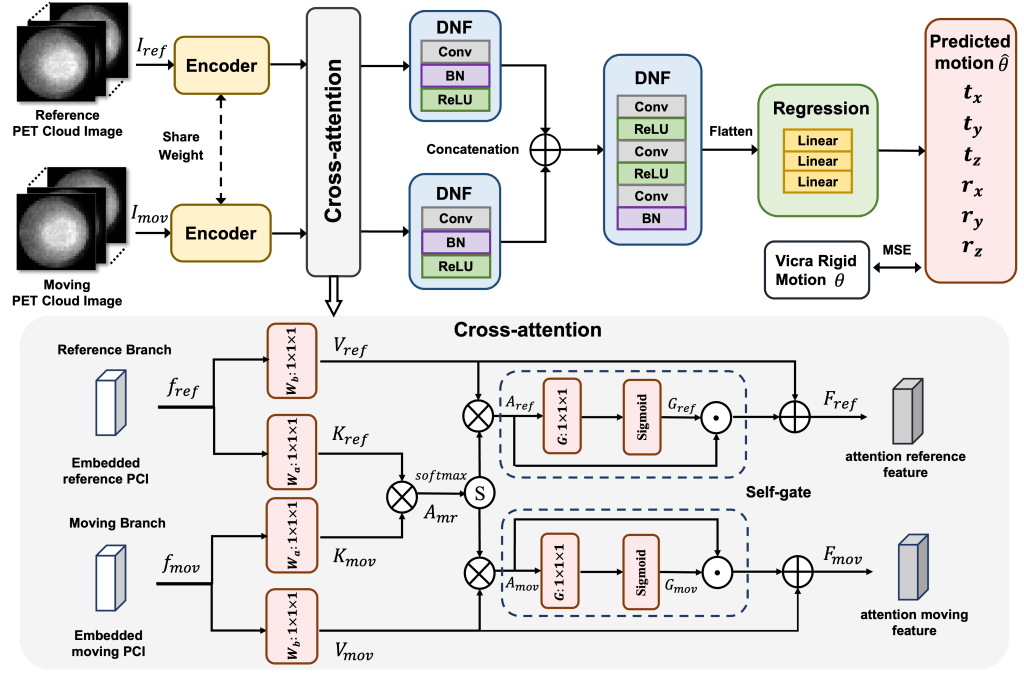
DL-HMC++ Framework: (Top) A shared encoder extracts imaging features from a pair of moving and reference 3D PET cloud images (PCIs). Then, the extracted features are fed into the cross-attention module to learn the correlation of anatomical features. Deep Normalization and Fusion (DNF) blocks refine the attention features both before and after concatenation. Finally, concatenated attention features are fed into a multi-layer perceptron Regression block to predict motion. (Bottom) Details of the cross-attention module
Evaluation: DL-HMC++ is evaluated on two PET scanners (HRRT and mCT) and four radiotracers (18F-FDG, 18F-FPEB, 11C-UCB-J, and 11C-LSN3172176) to demonstrate the effectiveness and generalization of the approach in large cohort PET studies.
Results: Quantitative and qualitative results demonstrate that DL-HMC++ consistently outperforms benchmark motion correction techniques, producing motion-free images with clear delineation of brain structures and reduced motion artifacts that are indistinguishable from ground-truth HMT. Brain region of interest standard uptake value (SUV) analysis exhibits average difference ratios between DL-HMC++ and ground-truth HMT to be 1.2%±0.5% for HRRT and 0.5%±0.2% for mCT.
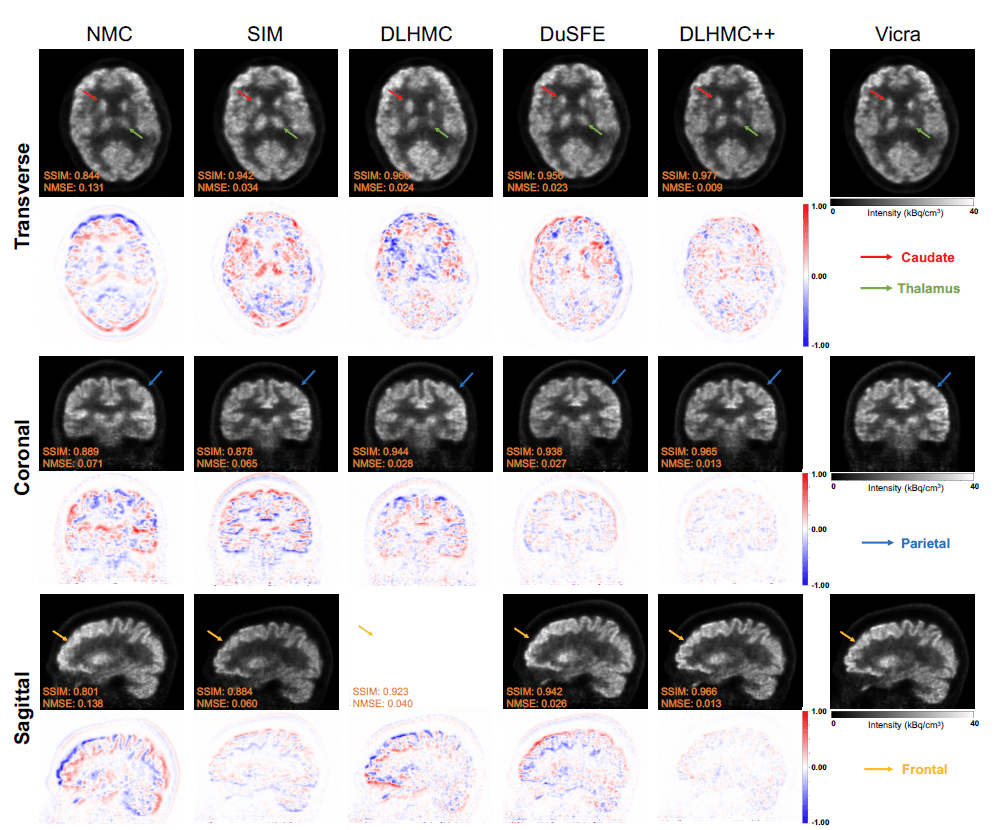
MOLAR Reconstruction comparison and error map between different MC methods for an HRRT 18F-FDG testing subject. Arrows on reconstruction images indicate the specific brain ROI for visual comparison
Remarks: The motion estimation methods in this study estimate transformation metrics from different images generated from PET raw data. Theoretically, motion parameters can also be directly estimated from sinograms, and it is feasible to employ deep learning algorithms for this purpose. However, part of their dataset includes TOF information, which causes the sinogram size to be much larger than the image size. In the future, the developers will explore the possibility of applying DL-HMC++ to other domains, such as sinograms and COD traces.
The proposed DL-HMC++ method exhibits certain limitations. Although DL-HMC++ achieves comparable motion tracking results with short half-life 11C tracers, it exhibits a notable constraint in its inability to effectively detect motion during periods of rapid tracer dynamic changes, such as the first 10 minutes post-injection. Moreover, Vicra failure and inaccuracy may have a negative effect on the proposed super- vised model. In the future, we aim to develop a generalized model for various tracers and scanners, including an ultra-high performance human brain PET/CT scanner, which has a spatial resolution of less than 2.0 mm and is more sensitive to motion effects. The developers will also investigate the feasibility of applying semi-supervised learning and unsupervised learning for PET head motion estimation.
Claim: DL-HMC++ demonstrates the potential for data-driven PET head motion correction to remove the burden of HMT, making motion correction accessible to clinical populations beyond research settings.
