Task: Enhance the accuracy of Alzheimer’s Disease (AD) classification by (1) implementing a Multimodal Neuroimaging (PET-MRI) Fusion fremwork using Discrete Wavelet Transform (DWT) to seamlessly combines structural MRI with functional PET images, and (2) developing a sophisticated Convolutional Neural Network (CNN) for AD classification employing the ensemble method to effectively aggregates outputs from multiple randomized neural networks thus significantly boosting diagnostic accuracy, enhancing robustness, and attaining superior computational efficiency, to ensure practical applicability in clinical scenarios.
Rationale: In the quest for more effective diagnostic methodologies for Alzheimer’s disease (AD), the integration of multimodal imaging techniques with advanced machine learning models holds significant promise.
In recent years, deep learning (DL), a subset of ML, has gained significant traction for its ability to learn hierarchical representations from raw data automatically. DL architectures, particularly convolutional neural networks (CNNs), have been at the forefront of medical image analysis, revolutionizing the field with their unprecedented accuracy and efficiency in tasks including AD diagnosis. CNNs are adept at automatically learning hierarchical representations from raw imaging data. This capability allows them to effectively capture spatial dependencies and extract discriminative features that are crucial for AD diagnosis, leading to heightened diagnostic accuracy [Ext. Ref.].
Furthermore, randomized neural networks such as random vector functional link (RVFL) [Ext. Ref.] networks have attracted attention for their efficiency and effectiveness in classifying AD. RVFL networks expand on the Extreme Learning Model (ELM) architecture by incorporating direct connections between input and output layers, which enhances the network’s capacity to capture complex patterns [Ext. Ref.], [Ext. Ref.]. These networks have demonstrated competitive performance compared to traditional ML and DL methods, while offering the benefits of faster training and reduced computational demands [Ext. Ref.], [Ext. Ref.]. Moreover, the integration of an Ensemble Deep RVFL (edRVFL) classifier [Ext. Ref.], which combines the outputs of multiple RVFL networks, addresses the variability and complexity inherent in AD symptoms and imaging characteristics. The ensemble approach boosts diagnostic robustness and enhances the model’s generalization capabilities across different patient demographics and imaging conditions.
FuseNET is a novel diagnostic framework that combines Discrete Wavelet Transform (DWT)-based fusion of MRI and PET images with a deep learning architecture to enhance the accuracy of AD classification. This approach has the potential to substantially enhance the diagnostic landscape for AD, leveraging the synergies of multimodal imaging, DL, and ensemble methodologies to create a more effective, reliable, and accessible diagnostic platform. The implications of these advancements extend beyond mere technical achievements, offering hope for earlier and more precise interventions that could alter the course of AD for millions of affected individuals worldwide.
The rationale for employing DWT in image fusion lies in its ability to perform multi-level decomposition, providing a flexible framework to selectively enhance or suppress features across different scales. This capability is particularly advantageous in medical imaging, where different modalities may excel in highlighting different aspects of pathology. This integrated approach enhances diagnostic accuracy and supports more informed treatment strategies for neurodegenerative diseases. The fusion approach incorporated in the proposed manuscript is represented in the figure below. Also, DWT remains a popular choice for PET–MRI fusion owing to its computational cost and its long record of clinical use [Ext. Ref.], [Ext. Ref.].

DWT based slice fusion approach outlining the fusion mechanism integrating axial MRI and PET slices for enhanced discriminative representation.
Description: FuseNET framework introduces several distinct and innovative contributions designed to significantly enhance AD diagnosis through an effective fusion of multimodal imaging data and advanced DL techniques. The primary contributions can be summarized as follows:
- Multimodal Neuroimaging Fusion using Discrete Wavelet Transform (DWT): Introduce a robust DWT-based image fusion method that seamlessly combines structural MRI with functional PET images. This technique significantly improves the clarity and resolution of fused images, allowing enhanced visualization of subtle pathological changes associated with the early onset of AD
- Attention-Enhanced CNN Architecture: Develop a sophisticated CNN consisting of ten layers, each equipped with integrated channel-spatial attention modules. These attention mechanisms dynamically focus on the most informative spatial regions and channel-wise features, significantly improving feature extraction accuracy and disease-specific information retrieval.
- Ensemble Classification using edRVFL: Propose an edRVFL network for the final disease classification step. Unlike conventional classifiers, this ensemble method effectively aggregates outputs from multiple randomized neural networks. This strategy significantly boosts diagnostic accuracy, enhances robustness, and achieves superior computational efficiency, ensuring practical applicability in clinical scenarios.
The utimate objective of the FuseNET framework is to contribute to the growing body of research on advanced neuroimaging and ML techniques for AD diagnosis, aiming to facilitate timely intervention and improve patient outcomes.
Image fusion integrates multiple images into a single image, retaining important features from each of the inputs. In medical imaging, especially with MRI and PET scans, fusion techniques are crucial for enhancing the visualization of structures and can potentially improve diagnostic accuracy.
The Discrete Wavelet Transform (DWT) is an advanced mathematical method that decomposes images into several frequency components across different resolutions, effectively capturing spatial and frequency information. This capability makes DWT particularly suitable for fusing neuroimaging data, such as MRI and PET scans, which require high precision and detail preservation.
DWT integrates the structural details from MRI with the functional insights from PET scans. This fusion is achieved by transforming both imaging modalities into wavelet coefficients. These coefficients segment the images into distinct frequency bands, enabling targeted enhancement and comprehensive integration of essential features from each modality. During the DWT process, images are processed through alternating high-pass and low-pass filters to separate the data into four distinct sub-bands: LL (Low-Low), LH (Low-High), HL (High-Low), and HH (High-High). Each sub-band represents different components of the image:
- First-Level Decomposition: Initially, the image data are split into the four sub-bands mentioned. The LL sub-band retains the approximate view, holding the major part of the image’s signal. In contrast, the LH, HL, and HH bands capture detailed aspects along vertical, horizontal, and diagonal orientations.
- Subsequent Decompositions: Further decomposition is applied recursively to the LL sub-band from the preceding level. With each step, the decomposition zooms into finer details, reducing resolution and enhancing the granularity of the analysis, which is crucial for capturing the subtlest details in neuroimaging.
The ability to analyze images at multiple scales is a significant advantage of using DWT in neuroimaging fusion. This method not only preserves the integrity of the original data but also enables precise targeting and blending of specific features from structural and functional scans. The end result is a synergistic composite that is greater than the sum of its parts, providing enhanced visibility of neurophysiological phenomena critical for early and accurate disease detection, such as Alzheimer’s.
By integrating DWT into the fusion process of MRI and PET images, the enriched visualization of the brain’s structure and function is facilitated, delivering a powerful tool for early diagnosis and continuous monitoring of neurological conditions.
The following steps are involved in DWT-based image fusion:
- Preprocessing: Both MRI and PET images are preprocessed to normalize the intensity ranges and remove any distortive artifacts. This step ensures that the inputs to the fusion process are in a suitable format for effective analysis.
- Decomposition: The decomposition stage of DWT-based image fusion is crucial for preparing medical images such as MRI and PET scans for fusion. The Haar wavelets are adopted as mother wavelets for their balance between smoothness and accuracy, which is crucial for medical imaging. Optimal decomposition is achieved at three levels, allowing for detailed yet efficient analysis. Each sub-band is processed using adaptive thresholding, with edge enhancement in the HL and LH bands and noise reduction in the HH band, using dynamically determined thresholds based on the median absolute deviation.
- Fusion Rule Application: The wavelet coefficients from the MRI and PET images are combined using fusion rules. These rules are designed to select the coefficients based on their energy, which represents the significance of the information they carry. The common fusion rules include max, min, average, and weighted average. Fusion of coefficients employs a weighted averaging method, where weights are calculated based on the local energy within a 3 × 3 pixel window, emphasizing detailed regions over smoother ones. Edge effects are minimized by symmetric padding, the width of which equals half the wavelet filter length, ensuring high fidelity in the reconstructed image. This methodologically rigorous approach enhances the diagnostic value of the fused images while maintaining the clarity and integrity of the data.
- Reconstruction: The fused wavelet coefficients are then reconstructed to form the final fused image. This step synthesizes all the combined information, reflecting both the anatomical and functional details captured by the MRI and PET scans, respectively.
Convolutional Neural Network (CNN) Architecture: In the pursuit of advancing AD diagnostics through imaging analysis, the proposed FuseNet framework introduces a sophisticated CNN enhanced by targeted attention mechanisms. This approach leverages the inherent strength of DL in feature detection and extraction, refined by the precision of attention models to focus on the most clinically relevant features within vast imaging datasets. Central to this strategy is the development of a CNN architecture specifically tailored to process multi-modal imaging data, extracting a rich tapestry of features that traditional methods might overlook. The addition of an attention module within this framework serves a dual purpose. Firstly, it acts to direct the network’s focus towards areas within the images that are more likely to exhibit signs of Alzheimer’s pathology. Secondly, it refines the feature set, ensuring that the subsequent classification layers are informed by the most discriminative features, enhancing both the accuracy and reliability of the diagnosis. This section will delineate the detailed architecture of our CNN, explain the integration of the attention mechanisms, and discuss their impact on the network’s performance, setting the stage for a new standard in medical image analysis. The architecture of the proposed approach has been visualized in the figure below, showcasing that the combination of residual blocks with multi-head attention mechanisms significantly enhances the discriminative feature extraction capacity of the proposed FuseNet, capturing critical structural and pathological biomarkers relevant to AD.

Comprehensive block diagram illustrating the proposed FuseNET framework architecture.
The section below elaborates on the architecture of FuseNet’s CNN, which is intricately designed to harness the power of DL for the efficient extraction and analysis of features from medical images. Moreover, it details the strategic incorporation of attention mechanisms that significantly enhance the network’s ability to focus on the most relevant features for AD classification.
FuseNet’s CNN is structured to include ten layers, each serving a specific function in the processing and refinement of image data. The network architecture is carefully crafted to progressively increase in complexity and capability, allowing for deep and meaningful extraction of features:
- Input Layer: Handles input images standardized to a size of 224 × 224 pixels, ensuring uniformity across all inputs.
- Convolutional Layers 1 to 10: Composed of convolutions with increasing numbers of filters, starting from 32 in the first layer and doubling in subsequent layers up to 128 in the fifth layer. Each convolutional layer employs 3 × 3 kernels, stride of 1, and padding to maintain size. These layers are equipped with ReLU activation functions to introduce non-linearity, and batch normalization is utilized to aid in stabilizing the learning process.
- Max Pooling: Applied after the first and second convolutional layers to reduce spatial dimensions by half, thus focusing on the most salient features while reducing computational load.
Multilayer channel-spatial attention for AD classification: In the context of AD classification, we extend the Spatial and Channel-wise Attention CNN framework, traditionally used to enhance the classification accuracy over fused MRI and PET image slices through a DL architecture comprising ten convolutional layers, each empowered with multilayer channel-spatial attention mechanisms. Our proposed CNN architecture incorporates ten convolutional layers where each layer is augmented with channel-spatial attention modules. This arrangement enhances the network’s capability to dynamically adjust its feature maps to focus more adeptly on specific, relevant features crucial for the accurate classification of AD stages from neuroimaging data. The dual attention mechanism modulates the extracted features both spatially and across channels at every convolutional layer. This is described by the following equations at each layer of the CNN:

where V_i is the feature map at layer l, and X_l-1 is the output from the previous layer. Channel attention selectively enhances the representation power of feature maps by focusing on informative channels, enabling the network to adapt its focus dynamically based on the relevance of each channel to the task at hand. Channel attention operates by processing the input feature maps to emphasize inter-channel dependencies without altering the spatial dimension. This is achieved by:
- applying global average pooling and max pooling to compress spatial information, resulting in two separate channel descriptors
- Passing these descriptors through a shared network, typically a small multilayer perceptron (MLP) with one hidden layer, to capture channel-wise dependencies
- the MLP outputs are then combined and passed through a sigmoid activation to generate channel attention weights.
Channel-wise attention is computed as:
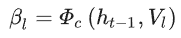
where φ_c is the channel-wise attention function, h_t-1 denotes the previous hidden state in the processing sequence, and β_l are the channel-wise attention weights.
Spatial attention complements channel attention by focusing on ‘where’ is crucial within the feature map, enhancing specific regions that contain important information for the task. Spatial attention assesses the importance of different spatial locations within the feature maps by:
- concatenating feature maps processed through channel-wise average and max pooling to highlight informative regions
- processing the concatenated maps through a convolutional layer followed by a sigmoid activation to produce a spatial attention map
Spatial attention weights are given by:

where Φ_s is the spatial attention function.
The resulting attention-modulated feature map at each layer is:

with γ_l representing the combined spatial and channel-wise attention weights, and f is a function that applies element-wise multiplication to merge the feature map with the attention weights.
Sequential application of channel-spatial attention across the ten layers ensures that each layer’s output optimally highlights critical features for AD classification, such as pathological markers evident in MRI and PET scans. This method builds a comprehensive representation of attentive features layer by layer, crucial for distinguishing between different stages of AD. This advanced attention mechanism is evaluated using AD classification tasks with fused MRI and PET images. The goal is to demonstrate that this multilayer, dual-attention approach can significantly outperform traditional classification methods by effectively utilizing both spatial and channel-wise data inherent in multimodal neuroimaging.
Adapting a 10-layer CNN with integrated multilayer channel-spatial attention for AD classification provides a robust framework for analyzing complex neuroimaging data. This method enhances the network’s sensitivity to subtle neuroanatomical variations associated with AD, facilitating more accurate and early diagnosis through DL technologies. Now, the critical features are fed to a feed-forward neural network for improvised classification instead of classification from a probability-based classifier.
Architecture of edRVFL: The edRVFL network architecture [Ext. Ref.], depicted in the figure below, serves multiple purposes which enhance its utility over traditional DL models. The design principles behind edRVFL are:
- Rich Feature Utilization: Unlike traditional models that only leverage features extracted from the final hidden layer for classification tasks, the edRVFL model harnesses both higher-level and intermediate features throughout the network. This approach aids in refining the decision-making process by providing a more detailed feature set for classification.
- Cost-Effective Ensemble: The ensemble within edRVFL is constructed by a single training session of a deep RVFL (dRVFL) network. This method incurs a marginally higher computational cost compared to training a solitary dRVFL model but remains substantially more resource-efficient than training multiple independent dRVFL models.
- Framework Flexibility: The edRVFL network maintains a high degree of flexibility, allowing for the incorporation of any variant of RVFL. This generic framework supports diverse applications and adaptations.

Architecture of edRVFL
The calculation of the output weight β_d in the dRVFL is tackled by matrix inversion, with sizes depending on the smaller of TxT or (N_L + d) x (N_L + d), where T is the training dataset size, L_ed represents the number of hidden layers, N is the number of hidden nodes per layer, and d denotes the dimensionality of the data. Typically, matrix inversion of a TxT matrix requires O(T^3) time and O(T^2) space.
The concept of training a single model to obtain multiple effective models, known as implicit ensembles, is paralleled in the edRVFL network. This approach resembles snapshot ensembling, where a neural network is trained under a cyclic learning rate schedule to converge at various local minima, capturing snapshots of the learning model parameters at each convergence. Unlike traditional ensembling that requires separate training instances, edRVFL achieves ensemble effects through its architecture, even though no learning rate adjustments are needed due to the closed-form solution training employed by RVFL networks. This enables the formation of ensembles if resources permit during the training phase.
Evaluation: The computational experiments were conducted on a system equipped with MATLAB , powered by an Intel(R) Core(TM) CPU at, with GB of RAM and Windows as an operating system. The ADNI dataset, which comprises structural MRI and PET images, was utilized for all experimental analyses. Samples from this dataset were randomly allocated in a split for training and testing purposes, respectively. The DL model processed a total of significant preprocessed slices selected as input. For the DL experiments, an attentive CNN model was employed, configured with specific hyperparameters to optimize performance. These parameters included a minibatch size of and a learning rate set at 0.05, using Adam as the optimization algorithm over epochs. Batch normalization is applied across the CNN layers to stabilize learning, while dropout is utilized to mitigate overfitting.
The attentive CNN model processed fused image slices to extract relevant features, which were then classified using an edRVFL network. This network configuration included hidden neurons distributed across hidden layers. The evaluation of the network’s performance, in comparison to other models, was consistently executed using the aforementioned setup and hyperparameters. The tuning of these hyperparameters was conducted using a combination of grid search and random search methods to evaluate model performance reliably. This approach allowed us to systematically explore a broad range of parameter combinations and identify the ones that resulted in the most predictive and stable models.
FuseNet model’s performance is compared against traditional classifiers and other single-layer feedforward networks.
Results: Fusion performance: In this comparative analysis among PET, MRI, and fusion-based imaging techniques, attentive CNN is employed to process each modality, with the classification performed by an edRVFL network. The results, detailed in the table below encompass metrics such as accuracy, specificity, sensitivity, and precision.
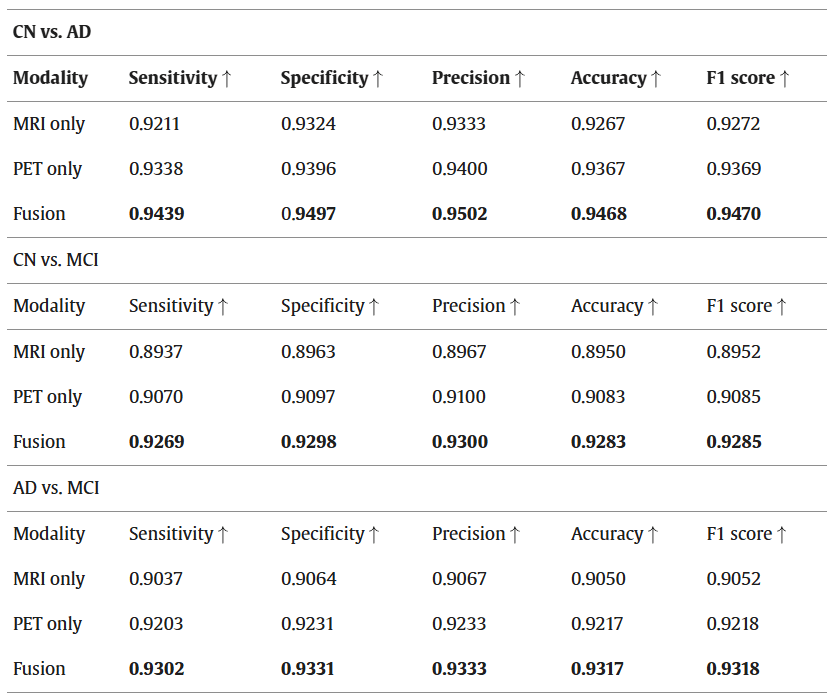
Performance comparison of the proposed model with different modalities.
Additionally, the first figure of this post presents these comparisons through confusion matrices. As indicated in the table above, fused images demonstrate significantly higher accuracy and are preferable compared to standalone MRI and PET images. The suboptimal performance of the MRI and PET modalities alone highlights the limitations of single-modality detection. To achieve more reliable results and enhance performance, a thorough validation of these findings is necessary. In the preprocessing phase, a crucial slice selection method converts 3D scan images into 2D, markedly reducing computational demands. Moreover, the implementation of the Wavelet fusion technique introduces minimal complexity to the system and requires only a brief duration to conduct tests, thereby optimizing both time and resource efficiency.
Classification performance: To validate the effectiveness of the proposed FuseNet model, we conducted a comprehensive performance comparison against a diverse set of traditional machine learning, single-layer neural networks, and modern deep learning models. Our evaluation included classifiers with and without attention mechanisms, with both unimodal and multimodal imaging inputs. Initially, we compared FuseNet against widely adopted baseline models such as RF, SVM, TWSVM, Decision Tree, Naïve Bayes, and -Nearest Neighbors (-NN), all of which operate on handcrafted or CNN-extracted features. Additionally, we evaluated CNN-based variants: a standard Softmax CNN and a CNN without attention but followed by an edRVFL classifier.
The comparison was extended to include recently proposed attention-driven and fusion-based architectures to further strengthen the experimental rigor. These include:
- 3D Attention-CNN [Ext. Ref.]: A deep convolutional model designed specifically for volumetric 3D MRI data, integrating spatial attention to improve early AD classification.
- Multimodal CNN + Softmax: A 2D CNN trained on DWT-fused MRI-PET slices, utilizing a Softmax classifier without attention or ensemble layers.
The classification results for the CN vs. AD task are summarized in the table below, showing metrics such as accuracy and F1 score. It is evident that the proposed FuseNet model achieves the highest performance across all evaluated methods, benefiting from (i) attention-guided hierarchical feature extraction, (ii) efficient multimodal fusion using wavelet transform, and (iii) ensemble-based classification via edRVFL.
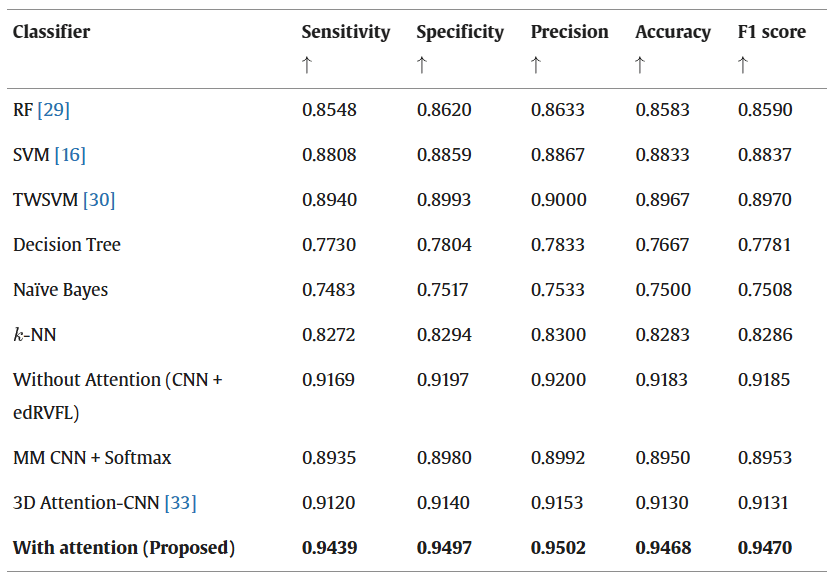
Performance comparison of the proposed model with several state-of-the-art classifiers for CN vs. AD.
The results demonstrate that FuseNet not only outperforms traditional machine learning models and shallow neural classifiers, but also consistently surpasses recent deep learning frameworks in terms of diagnostic accuracy and F1 score. This superior performance can be attributed to its unified design—combining attentive feature extraction, efficient MRI-PET slice-level fusion, and ensemble classification. Moreover, the inclusion of attention modules within each convolutional layer improves the proposed model’s capacity to focus on diagnostically relevant regions, while the edRVFL classifier ensures robust generalization by aggregating multi-depth feature responses. These design elements collectively contribute to FuseNet’s effectiveness in automated Alzheimer’s disease diagnosis.
Randomized Networks Performance: In this subsection, various RVFL variants, including dRVFL and edRVFL, are evaluated and compared along with other notable randomized networks such as RVFL with a direct link (RVFL_dl), RVFL without a direct link (RVFL_wdl). This comparison is essential to highlight the enhancements achieved through the ensemble model incorporated into our proposed model. We present a detailed comparison of these models, focusing on key performance metrics like accuracy, sensitivity, specificity, and precision. The outcomes are systematically presented in the table below, illustrating the effectiveness of each model and the impact of optimization on classification accuracy.

Performance comparison of the suggested model with several SLFN models (in %) for CN vs. AD classification.
Claims: The proposed FuseNet model offers substantial technical improvements over both classical ML methods and traditional DL architectures. Classical classifiers such as RF, SVM, and TWSVM primarily rely on hand-crafted features. They are constrained by their limited ability to model complex, high-dimensional patterns present in neuroimaging data. In contrast, FuseNet leverages a 10-layer CNN with channel-spatial attention, allowing the proposed model to learn hierarchical, data-driven representations automatically. This architectural choice enables more precise identification of subtle neuroanatomical and metabolic alterations characteristic of early-stage AD, which classical methods may fail to capture.
Compared to baseline DL models such as Softmax-CNN and CNN without attention, the proposed FuseNet introduces targeted feature refinement through integrated attention mechanisms. While standard CNNs extract hierarchical features, they treat all spatial locations and channels equally, potentially diluting the influence of diagnostically salient regions. In the proposed FuseNet model, channel attention emphasizes feature maps corresponding to critical brain regions, while spatial attention focuses the model’s resources on the most informative local structures, thereby significantly enhancing diagnostic sensitivity.
Regarding classification strategy, the edRVFL network employed in the proposed FuseNet model offers notable advantages over traditional ensemble methods such as RF. Unlike RF, which aggregates decisions from independently trained trees, edRVFL aggregates rich intermediate features generated at multiple depths of the CNN in a single forward pass without iterative backpropagation. This design reduces computational complexity while maintaining or even improving generalization performance. Moreover, edRVFL circumvents the need for expensive kernel computations inherent to SVM-based models, making it particularly suitable for large neuroimaging datasets.
From a computational perspective, the proposed FuseNet effectively balances efficiency and accuracy. DWT for slice fusion significantly reduces the dimensionality of multimodal imaging data, allowing for lightweight yet information-rich inputs to the network. Combined with a 2D CNN structure instead of a full 3D CNN, this reduces both memory requirements and training time, facilitating real-time diagnostic applications without compromising predictive performance.
Beyond technical improvements, the proposed model is carefully designed for practical clinical deployment. The DWT-based multimodal slice fusion reduces dimensionality while preserving critical anatomical and metabolic features from MRI and PET scans. The computational burden is substantially reduced by processing 2D fused slices rather than complete 3D volumes. Additionally, the edRVFL classifier aggregates intermediate CNN representations through a single-pass, closed-form solution without requiring backpropagation across multiple epochs, further accelerating inference. These choices enable low-latency predictions ( <0.2 s per slice) and minimize memory footprint, making the model well-suited for integration with clinical workstations and emerging edge-computing devices.
The application of DWT in multimodal image fusion offers critical benefits. The wavelet decomposition captures complementary spatial and frequency information from MRI and PET modalities, enriching the fused images with both anatomical and functional characteristics crucial for early AD detection.
Compared to simple image concatenation or intensity averaging, DWT preserves localized pathological features, such as hippocampal atrophy and hypometabolic regions, which are pivotal markers of disease progression. Furthermore, the DWT-based fusion operates with minimal computational overhead and avoids introducing significant latency into the preprocessing pipeline, aligning with the model’s goal of real-time applicability.
Remarks: Although the current FuseNet framework demonstrates strong performance and efficiency, future work will focus on further enhancements. First, the developers plan to explore pruning techniques and lightweight attention mechanisms (such as Squeeze-and-Excitation blocks) to reduce CNN complexity while maintaining diagnostic sensitivity. Second, large-scale validation across multi-center cohorts will be pursued to assess model generalizability across different demographic and acquisition variations. Third, they aim to optimize the model for deployment on edge-computing platforms and to explore its extension to longitudinal data for disease progression prediction. Such enhancements will further solidify the proposed FuseNet as a clinically practical and scalable solution for Alzheimer’s disease diagnosis.
