Task: To synthesize a reference late cardiac Rb-82 PET image frame from a set of respective early PET image frames for improved inter-frame registration, motion correction and myocardial blood flow (MBF) quantification.
Description: TAI-GAN: Temporally and Anatomically Informed Generative Adversarial Network is a model aiming to transform the early cardiac PET image frames of a dynamic Rb-82 PET acquisition into a respective late reference frame using an all-to-one mapping approach, by taking into account both the temporal and spatial distribution of Rb-82 uptake signal in several heart regions (e.g. right- and left-ventricle and the myocardium) across dynamic cardiac PET image frames. Specifically, a feature-wise linear modulation layer encodes channel-wise parameters generated from temporal tracer (in this case Rb-82) kinetics information, and rough cardiac segmentations with local shifts serve as the anatomical information. According to the model’s reference publication, TAI-GAN has been the first model incorporating both temporal and anatomical information into the GAN for dynamic cardiac PET frame conversion, with the ability to handle high tracer distribution variability and prevent spatial mismatch.
The structure of the proposed network TAI-GAN is illustrated in the figure below. The generator predicts the related late frame using the input early frame, with the backbone structure of a 3-D U-Net (4 encoding and decoding levels), modified to be temporally and anatomically informed. The discriminator analyzes the true and generated late frames and categorizes them as either real or fake, employing the structure of the PatchGAN model (3 encoding levels, 1 linear output layer).

To address the high variation in tracer distribution in the different phases, the temporal information related to tracer dynamics is introduced to the network by concatenating RVBP and LVBP TACs as well as the frame temporal index in one-hot format. A long short-term memory (LSTM) layer encodes the concatenated temporal input, and the following 1-D convolutional layer and linear layer map the LSTM outputs to the channel-wise parameters γ and β. The feature-wise linear modulation (FiLM) layer then manipulates the bottleneck feature map by applying to each map channel i first a scaling and then a shifting operation using a channel-specific set of γi and βi parameters as the scaling factor and shift distance, respectively.
The dual-channel input of the generator is the early frame concatenated with the rough segmentations of RVBP, LVBP, and myocardium. It should be noted that the cardiac segmentations are already required in MBF quantification and this is an essential part of the current clinical workflow. For the partocular model, the labeled masks serve as the anatomical locator to inform the generator of the cardiac ROI location and prevent spatial mismatch in frame conversion. This is especially helpful in discriminating against the frame conversion of early RV and LV phases. Random local shifts of the segmentations are applied during training. This improves the robustness of the conversion network to motion between the early frame and the last frame.
Both an adversarial loss and a voxel-wise mean squared error (MSE) loss are included as additive terms in the aggregated loss function of the TAI-GAN model. The discriminator aims at maximizing the loss function, while the generator aims at minimizing the discriminator’s selected loss.
Evaluation: The proposed method was validated on a clinical dataset of 85 clinical Rb-82 PET scans (55 rest and 30 regadenoson-induced stress) that were acquired from 59 patients at the Yale New Haven Hospital using a GE Discovery 690 PET/CT scanner and defined by the clinical team to be nearly motion-free, with Yale Institutional Review Board approval. After weight-based Rb-82 injection, the list-mode data of each scan for the first 6 min and 10 s were rebinned into 27 dynamic frames (14 × 5 s, 6 × 10 s, 3 × 20 s, 3 × 30 s, 1 × 90 s), resulting in a total of 2210 early-to-late pairs.
All the early frames with LVBP activity higher than 10% of the maximum activity in TAC are converted to the last frame. Very early frames with lower activity in LVBP are not considered as they do not have a meaningful impact on the image-derived input function and subsequently the associated MBF quantification. Prior to model input, all the frames were individually normalized to the intensity range of [−1,1]. Patch-based training was implemented with a random cropping size of (64,64,32) near the location of LV inferior wall center, random rotation in the xy plane with the range of [−45∘,45∘], and 3-D random translation with the range of [−5,5] voxels as the data augmentation.
Considering the low feasibility of training each one-to-one mapping for all the early frames, two pairwise mappings were trained using a vanilla GAN (3-D U-Net generator) and solely the adversarial loss as a comparison with the state-of-the-art method by Sundar et al. Denoting as EQ the first frame when LVBP activity is equal to or higher than RVBP activity, the two specific mappings 1-to-1 early-to-late frame mappings are involving as early frames one frame before (EQ-1) and one frame after (EQ+1) the EQ frame, respectively. The vanilla GAN and the MSE loss GAN were also implemented as two all-to-one conversion baselines. More details regarding their evaluation with ablation studies can be found in the model’s reference publication supplementary material.
All the deep learning models are developed using PyTorch and trained under 5-fold cross-validation on an NVIDIA A40 GPU using the Adam optimizer (learning rate G = 2e−4, D = 5e−5). In each fold, 17 scans were randomly selected as the test set and the remaining 68 were for training. The stopping epoch was 800 for one-to-one mappings and 100 for all the all-to-one models.
Image conversion evaluations include visualizing the generated last frames against the real last frame and the input frame, with overlaid cardiac segmentations. Quantitatively, the MSE, normalized mean absolute error (NMAE), peak signal-to-noise ratio (PSNR), and structural similarity index (SSIM) are computed between the generated and real last frames.
Since all the included scans are categorized as motion-free, a motion simulation test was run to evaluate the benefit of frame conversion on motion correction using the test set of one random fold, resulting in 17 cases. On an independent Rb-82 cardiac scan cohort identified as having significant motion by the clinical team, non-rigid motion correction was run in BioImage Suite (BIS) to generate realistic motion fields. The motion field estimations from the late frames were scaled by a factor of 2 and then applied to the motion-free test frames as motion ground-truth. In this way, the characteristics of simulated motion match with real-patient motion and also have significant magnitudes. In parallel, the different image conversion methods were applied to the early motion-free frames prior to motion simulation followed by application of the same simulation motion fields. All original and converted frames with simulated motion were then registered to the last reference frame using BIS with the settings as in Guo et al.
After motion estimation, the predicted motion of each method is applied to the original frames without intensity normalization for kinetic modeling. To estimate the uptake rate K1, the LVBP TAC as the image-derived input function and myocardium TAC were fitted to a 1-tissue compartment model using weighted least squares fitting. MBF was then calculated from K1 under the relationship as in Germino et al. The percentage differences of K1 and MBF were calculated between the motion-free ground-truth and motion-corrected values. The weighted sum-of-squared residuals were computed between the MBF model predictions and the observed TACs.
Results: The model’s reference study presented results demonstrating that TAI-GAN can produce converted early frames with high image quality, comparable to the real reference frames. After TAI-GAN conversion, motion estimation accuracy and clinical myocardial blood flow (MBF) quantification were improved compared to using the original frames.
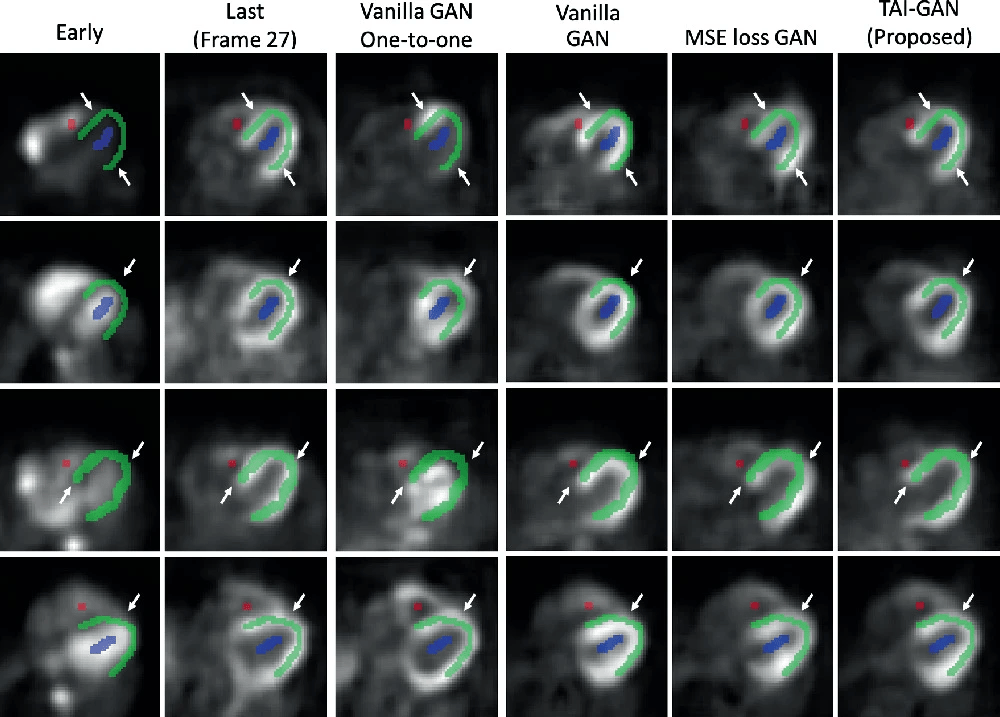
The sample results of the early-to-late frame conversion by each method are illustrated in the figure below. Although the one-to-one models were trained under the most specific temporal mapping, the prediction results were not satisfactory and showed some failure cases, possibly due to the small sample size and the insufficient kinetics information of a given early frame. Among the all-to-one models, vanilla GAN was able to learn the conversion patterns but with some distortions. After introducing MSE loss, the GAN generated results with higher visual similarity. After introducing temporal and anatomical information, the visual performance of the proposed TAI-GAN was the best with less mismatch and distortion.
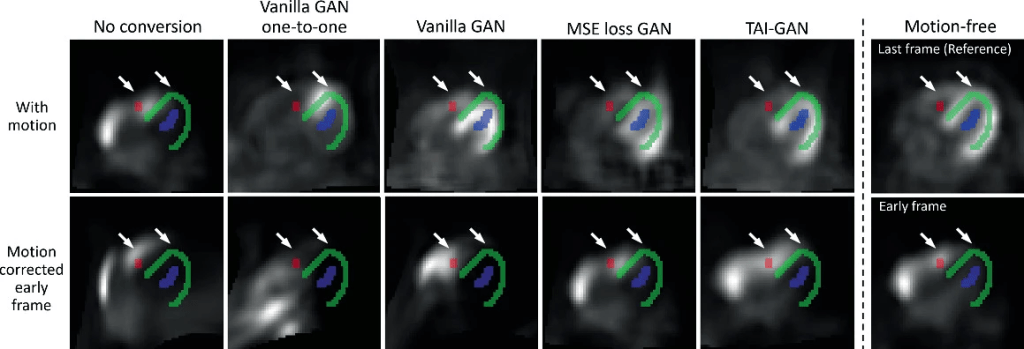
Sample motion simulation and correction results are shown in the figure below. The simulated non-rigid motion introduced distortion to the frames and the mismatch between the motion-affected early frame and the segmentation is observed. After directly registering the original frames, the resliced frame was even more deformed, likely due to the tracer distribution differences in the registration pair. Early-to-late frame conversion could address such challenging registration cases, but additional mismatches might be introduced due to conversion errors, as seen in the vanilla and MSE loss GAN results. With minimal local distortion and the highest frame similarity, the conversion result of the proposed TAI-GAN matched the myocardium and ventricle locations with the original early frame and the registration result demonstrated the best visual alignment.
Claim: TAI-GAN, is a temporally and anatomically informed GAN model for early-to-late frame conversion to aid dynamic cardiac PET motion correction. The TAI-GAN can successfully perform early-to-late frame conversion with desired visual results and high quantitative similarity to the real last frames. Frame conversion by TAI-GAN can aid conventional image registration for motion estimation and subsequently achieve accurate motion correction and MBF estimation. Future work includes the evaluation of deep learning motion correction methods and real patient motion as well as the validation of clinical impact using invasive catheterization as the clinical gold standard.
TAI-GAN is based on the conditional DCGAN (cDCGAN) model. More technical details can be found in cDCGAN Reference Publication.
