Task: Generate synthetic high-resolution PET images from low-resolution PET images
Description: QSDL is a quasi-supervised deep learning method, which is a new type of weakly-supervised learning methods, to recover high-resolution (HR) PET images from low-resolution (LR) counterparts by leveraging similarity between unpaired LR and HR image patches. Specifically, LR image patches are taken from a patient as inputs, while the most similar HR patches from other patients are found as labels. The similarity between the matched HR and LR patches serves as a prior for network construction. In fact, supervised and unsupervised network models can be considered as special cases of the proposed quasi-supervised approach.
The proposed method can be implemented by designing a new network or modifying an existing network. As an example in this model version, the developers have modified the cycle-consistent generative adversarial network (CycleGAN) for super-resolution (SR) PET. The model’s code is publicly available on GitHub.
The proposed quasi-supervised learning method consists of the following steps:
- Acquire a large number of unpaired LR and HR images of many patients.
- Divide them into patches containing meaningful local information.
- Find best-matched patch pairs from LR and HR patches according to their similarity.
- Train a neural network to learn guided by the matched patch pairs and corresponding matching degrees.
Local information processing and neural network construction are the two main elements of the proposed approach for super-resolution PET.
The representation and matching of local information are critically important. The former needs to be in a form that can be accessible to machine, and the latter mimics human perception of similarity with a proper metric. Fortunately, patches extracted from a whole image can often represent local features well, and many metrics measure similarity between two patches.
For given unpaired LR and HR PET images, our goal is to find the most similar patch pairs in LR and HR respectively and form a large set of such paired patches. Given the large number of patches, direct matching will undoubtedly impose a heavy computational burden. To reduce the computing overhead, we perform the patch matching task at the three levels: patient matching, slice matching, and patch matching. The workflow is shown in the figure below:

which entails an efficient multi-scale workflow:
- For a patient in an LR image set, find a most similar patient in an HR image set by calculating similarity between the images in the LR and HR image sets.
- For a given slice in the LR image volume, find best-matching slice in the corresponding HR image volume.
- For a given patch in the LR slice, find best-matching patch in the corresponding HR slice.
- For the corresponding LR and HR patch pairs, compute and store their similarity information.
During the matching process, normalized mutual information (NMI), Pearson correlation coefficient (PCC), radial basis function (RBF), and other functions may be used to measure similarity between two image patches.
While the goal is to find the most similar patch pairs, the additional two steps, patient and slice matching, improve the matching efficiency at a cost of potentially reduced accuracy. Therefore, when a dataset is small or computational power is sufficient, these two steps can be removed entirely or partially for the best matching results. The accuracy of data matching certainly depends on the sample size; that is, the larger dataset, the better matching results. The utilization of data in supervised learning involves only two cases, paired and unpaired. In contrast, quasi-supervised learning treats the matching degree as a probability distribution; i.e., the higher the similarity, the higher the probability of matching, which is more aligned with human fuzzy reasoning.
After obtaining a large number of patch pairs and the corresponding similarity measures, the next step is to construct a neural network. An important advantage of the proposed quasi-supervised learning approach is that it can be implemented by modifying existing networks. We take CycleGAN as an example to showcase the proposed method, which is called CycleGAN-QL.
Given the LR and HR image domains X and Y, CycleGAN consists of two mappings G:X→Y and F:Y→X. It also introduces two adversarial discriminators Dy and Dx, which determine whether the output of a generator is real or not. For example, given an LR image x∈X, G learns to generate an HR image y′ that closely resembles a true HR image y and thus deceives Dy. Analogously, Dx tries to distinguish the fake output x′ of F from a true x. To regularize the mapping between source and target domains, the network is empowered with four types of loss functions: adversarial loss LADV, cycle consistency loss LCYC, identity loss LIDT, and quasi-supervised loss LQL.
The overall objective of the model is to optimize the two generators G and F and their corresponding discriminators as follows:
LCycleGAN-QL = LADV(G,F) + λ1LCYC + λ2LIDT + λ3LQL
where λ1, λ2 and λ3 are hyperparameters that specify the share of each loss. Τhe proposed CycleGAN-QL model is illustrated in the figure below:
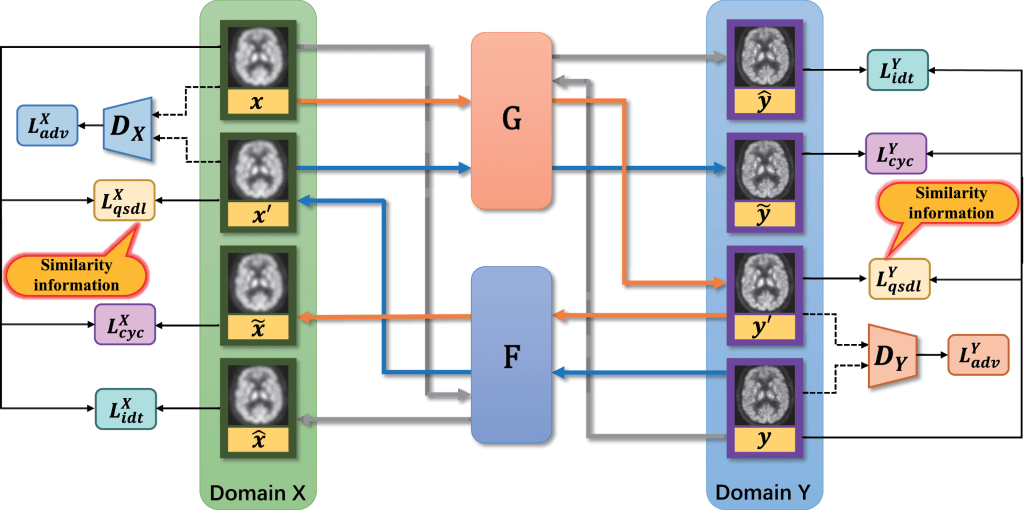
The structures of networks G, F and D are the same as those used in CycleGAN (Xue et al., 2021). First, the generators G and F have the same structure, which can be decomposed into three parts: feature extraction, transformation and reconstruction.
- The feature extraction part represents a given image as feature maps for transformation.
- Then, the transformation part produces the final feature maps for the reconstruction part to generate an output image. Specifically, the feature extraction part consists of six convolutional layers, each of which is followed by an instance norm module and a leaky ReLU activation module. The transformation part uses five residual block modules.
- The reconstruction part consists of two deconvolutional layers and four convolutional layers, all of which are followed by instance normalization and leaky ReLU activation.
Additionally, there is one convolutional kernel in the last convolutional layer, which is the output of the network. The size of all convolutional kernels in the network is 3 × 3.
In the discriminator, each convolutional layer is followed by an instance norm module and a leaky ReLU activation module except for the last two fully connected layers. The first fully connected layer has 1,024 units followed by leaky ReLU activation. Since the least square loss is employed between the estimated and true images, no sigmoid cross entropy layer is applied. Only a fully connected layer with one unit is used as the output. Similar to the generator, convolutional kernels of size 3 × 3 are applied in all convolutional layers. The number of convolutional kernels in each layer is 32, 32, 64, 64, 128, 128, 256 and 256 respectively.
Data: To evaluate the performance of quasi-supervised learning, we designed experiments based on the Brain PET Image Analysis and Disease Prediction Challenge dataset, which consists of 15,000 brain PET images of 128 ×128 and 168 × 168 pixels from elderly volunteers.
Results: The model’s reference publication presents numerical and experimental results that qualitatively and quantitatively show the merits of the proposed method relative to the state-of-the-art methods, especially in terms of flexibility and effectiveness.
The proposed CycleGAN-QL was compared with the state-of-the-art methods including total variation (TV) (Song et al., 2020a, Song et al., 2019), GAN (Goodfellow et al., 2014, Goodfellow, 2016), ADN (artifact disentanglement network) (Liao et al., 2019), CycleGAN and DualGAN (Yi et al., 2017). TV is a classic algorithm for super-resolution and denoising in the image domain. ADN is an unsupervised deep learning-based method for CT artifact reduction. GAN, CycleGAN and DualGAN are successful unsupervised deep-learning methods for image-to-image translation tasks. Except for TV, the methods were trained directly using the original unpaired data, while the proposed method was trained using matched data.
To qualitatively demonstrate the performance of the proposed method, a representative image is shown in the figure below. It can be seen that all the methods improved image resolution of the original image except for TV, which produced blurry results like the LR image. Additionally, DualGAN and CycleGAN, especially GAN, lost feature details in the image. In contrast, our CycleGAN-QL reconstructed the image closest to the true image and recovered most details. In terms of PSNR and SSIM, the conclusion remains the same.

Additionally, the difference images were obtained by subtracting the generated image from the reference image in figure below, leading to a conclusion consistent with the above comments.

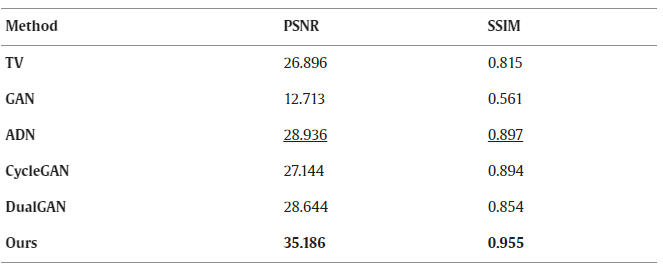
The quantitative results from the various methods on the whole testing set are listed in the table below. It can be seen that the proposed method produced the images with the highest PSNR and SSIM in general. Although ADN provided the second-best results, significantly below our results, and CycleGAN and DualGAN had very similar performance with ADN. Unexpectedly, GAN presented the worst numerical result, which even is lower than that of TV. In other words, the proposed method can produce a perceptually pleasing yet quantitatively accurate result, outperforming the other state-of-the-art methods.
Claim: Inspired by the fact that images can be mismatched but similar patches in the images can be often found, this model developers have proposed a quasi-supervised approach to produce PET image super-resolution with unpaired LR and HR PET images. Their method is compatible with either supervised or unsupervised learning, and can be implemented by designing a new network or modifying an existing network, making it applicable in a wider range of applications. This method provides a new way of thinking for computationally upgrading legacy equipment and intelligently developing novel PET scanners. As a matter of fact, the method is not limited to PET image super-resolution and can be extended to other super-resolution and other tasks.
