Task: Blind Noise Removal in Real Images
Description: The FAN (Frequency Attention Network) model implements a method for blind image denoising that combines frequency domain analysis and attention mechanism, The wavelet transformation is adapted to convert images from spatial domain to frequency domain with more sparse features to utilize spectral information and structure information. For the denoising task, the objective of the neural network is to estimate the optimal solution of the wavelet coefficients of the clean image by nonlinear characteristics, which makes FAN possess good interpretability. Meanwhile, spatial and channel mechanisms are employed to enhance feature maps at different scales for capturing contextual information. Extensive experiments on the synthetic noise dataset and two real-world noise benchmarks indicate the superiority of our method over other competing methods at different noise type cases in blind image denoising.
Deep CNN denoisers significantly improve image denoising performance on synthetic noise model but tend to be over-fitted to the realistic noise model like additive white Gaussian noise (AWGN). When applied on the real-world denoising task, they are lack of the ability to eliminate both signal-dependent noise and signal-independent noise. Thus, real-world denoising is still a challenging task since noise distributions vary a lot in different scenes.
The developers of the FAN model attempt to tackle this issue by developing a frequency attention network which combine frequency domain analysis and a deep CNN model for the image denoising task. From the perspective of Fourier, image transformation methods that can enhance the performance of the network are essentially changing the frequency domain information of the image to enhance the feature. Motivated by this perspective and sensitivity of frequency components in human visual system (HVS) , the wavelet transformation is employed to extract the spectral information and structure information of images as the prior information of the network. The wavelet transform can preserve the structural information of the image and facilitate high-dimensional features for image restoration.
Flexibility and robustness are still significant problems for most denoising methods. Past studies (Zhang et al, Guo et al ) introduced the noise map to train denoising networks jointly which can provide more information to help extract image features. This concepted was adopted by the FAN model to accelerate its network training. The spatial attention mechanism is combined with the channel attention mechanism to enhance the feature map for improving the feature extraction ability of the network and removing signal-dependent noise. At last, the influence of different individual components of the network and different wavelet basis functions are also explored.
To sum up, the contributions of the FAN model, as presented in the model’s reference publication, are following:
- proposal of the concept of frequency attention networks (FAN) combining traditional signal processing methods and deep learning, which makes the method based on neural network more interpretable from the perspective of frequency domain.
- introduction of the Spatial-Channel Attention Block which combines the spatial attention and channel attention mechanisms to enhance feature maps and help to better extract the main features of the image.
- evaluation of the effect of different wavelet basis functions on denoising performance and experiments to show that Haar wavelet with symmetry, orthogonality and compactly supported characteristics can achieve the best result.
- experiments on synthetic noise datasets and real noise datasets respectively to prove the superiority of the model compared with competing methods and to achieve state-of-the-art results.
The FAN model presentation in its reference publication consists of data pre-processing, networks architecture and attention design. The FAN architecture includes the Est-Net and De-net network models. Est-Net is employed for the estimation of the noise level map which plays the role of guidance. De-Net is for image denoising. Then, the effects of the wavelet transform characteristics on network performance are analyzed. Finally, the concept of the Spatial-Channel Attention Block (SCAB) used for feature map enhancement is introduced.
Inspired by the observation that human visual system (HVS) is more sensitive to the spatial resolution of the luminance signal than that of the chrominance signal and HVS has the varying sensitivity to different frequency components, the FAN model developers converted the image from the RGB color space to the YCbCr color space for denoising.
As shown in the figure below, the FAN network contains two subnetworks including the noise estimation network and the denoising network. Est-Net takes the noisy image as input and estimates different noise level map for each channel. Est-Net is composed of five full-convolutional layers, each consisting of only the Conv and Parametric ReLU (PReLu) layers excluding the batch normalization layer and the pooling layer. The filter size is 3×3 and the feature map is set as 64. The noise map which can improve network flexibility and generalizability for different noise levels is also conductive to increase the convergence speed of the network because its redundancy can help to better extract image features.

In the denoising network, the input RGB images are transformed to the YCbCr color space including luminance Iy and chroma Iuv. Considering the sensitivity of the human visual system to luminance, Iy is converted to the frequency domain by wavelet transform for reserving spectral information and structure information while Iuv stays original. We concatenate the processed data and noise map to get I′ as input to the De-Net network which contains 4 encoder blocks and 3 decoder blocks and there is a skip connection to concatenate two blocks under the same scale.
The U-Net structure can use feature fusion at different resolutions to obtain better contextualized representations, but it will cause the loss of image details at high resolution when the network depth at each scale is consistent. Aiming at retaining more details, the variable depth design is adopted for De-Net where the numbers of residual convolutional blocks at different scales increase with the resolution to ensure that our network can obtain a stronger expressive ability. Besides, the SCAB module is added after each encoder for feature enhancement. Finally, the complete denoised image is obtained by wavelet reconstruction and converted to the RGB color space.
Wavelet is an important tool for the analysis of unstable signals while the image as a 2D plane unstable signal is well suited for study with the wavelet. Wavelet transformation of one image decomposes the image into different sub-bands based on the frequency information and the processing of the medium and the high frequency sub-bands can result in noise removal. The learning objective of the FAN neural network can be abstracted as the optimal solution to the wavelet coefficients defining the network output. These coefficients can be estimated with the help of the nonlinear characteristics of the neural network and auxiliary noise map by deep learning to restore the image as close as possible to ground truth.
Separable wavelets which are widely used for two-dimension wavelet transformations generally use orthogonal wavelets. In the case of discrete signal, discrete orthogonal wavelets possesses the completeness required to retain all the energy of the image signal in the transformation process. Meanwhile, orthogonal wavelets can reduce the data correlation between different sub-bands. Therefore, using wavelet to transform the image into the frequency domain will not lose any information. Instead, it can use the frequency characteristics of the image signal in the frequency domain to help the deep convolutional network extract its nonlinear characteristics.
Signal-independent noise can be easily filtered out from the wavelet sub-band through neural network learning, but signal-dependent noise is not easy to remove because of the high correlation between high-frequency signal and noise. In order to make full use of the inter-channel and inter-spatial relationships of the image, we used a Spatial-Channel Attention Block to extract the features in the convolutional stream. The schematic of SCAB is shown in the figure below. We extracted the distribution of noise levels through Est-Net and also characterized the structure information of noise which we can use spatial attention mechanism to refine features map of Iy. Meanwhile, the channel attention mechanism is applied on Iy to achieve the feature recalibration.
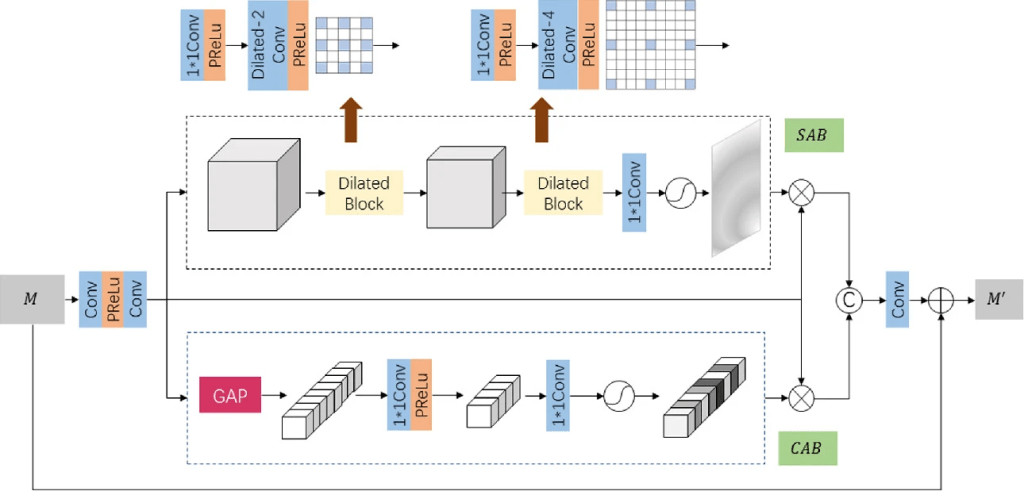
Spatial attention is used for the extraction of the inter-spatial relationship of images. A progressively expanding multi-layer convolution operation is employed to obtain an effective tradeoff between model complexity and performance. Dilated convolution and expanding filter kernel size are adopted to increase the receptive field, and gradually decreasing channels reduce the computational complexity.
Channel attention utilizes the squeeze and excitation operations to enhance the main features of the feature map based on the inter-channel relationship. For an input feature map, the channel-by-channel statistics are initially generated through global pooling as the squeeze operation. This statistic expresses the entire image under this type of feature extraction convolution kernel global description. The excitation operation is used for fully capturing the dependencies between channels through two convolutional layers with the sigmoid gating.
Evaluation: Various ablation studies were designed to demonstrate effectiveness of the FAN model’s strategy and evaluate its performance on synthetic and real noise datasets compared with previous outstanding methods.
The SIDD real noise dataset and synthetic noise datasets are employed as the training dataset, respectively. Each image is cropped to a size of 128 * 128 * 3 as input, each epoch trained 96000 images and 50 epochs trained each time. We adopt Adam as the optimizer with β1 = 0.9, β2 = 0.999 while we set initial learning rate as 2e-4 and adopt the cosine annealing strategy with the final learning rate as 5e-10. The hyper-parameter γ is set as 0.2 both for real-noise and synthetic noise training.
Results: The Table below shows the results of an ablation study on the impact of different architectural components including wavelet transform, SCAB, noise map and variable depth when testing on the SIDD validation dataset.

Compared with the spatial domain image as input, the wavelet transform can simultaneously assemble frequency domain information and spatial structure information for learning and improves the network performance by 0.16 dB. Wavelet decomposition essentially regards the wavelet basis function as a filter to decompose the image into different frequency bands. This operation can also be learned by the neural network without wavelet transformation. However, the Haar wavelet with orthogonality, compactly supported and symmetry provides a certain prior constraint for the image to help the network pay attention to the frequency domain information of the image during training process.
An example of image quality performance results on images with synthetic additive Gaussian White Noise (AWGN) from the LIVE1 public dataset is presented in the figure below:

Below is an image quality performance example on a real image from the real-world noise SIDD public dataset:

Below is an image quality performance example on a real image from the real-world noise DND public dataset:
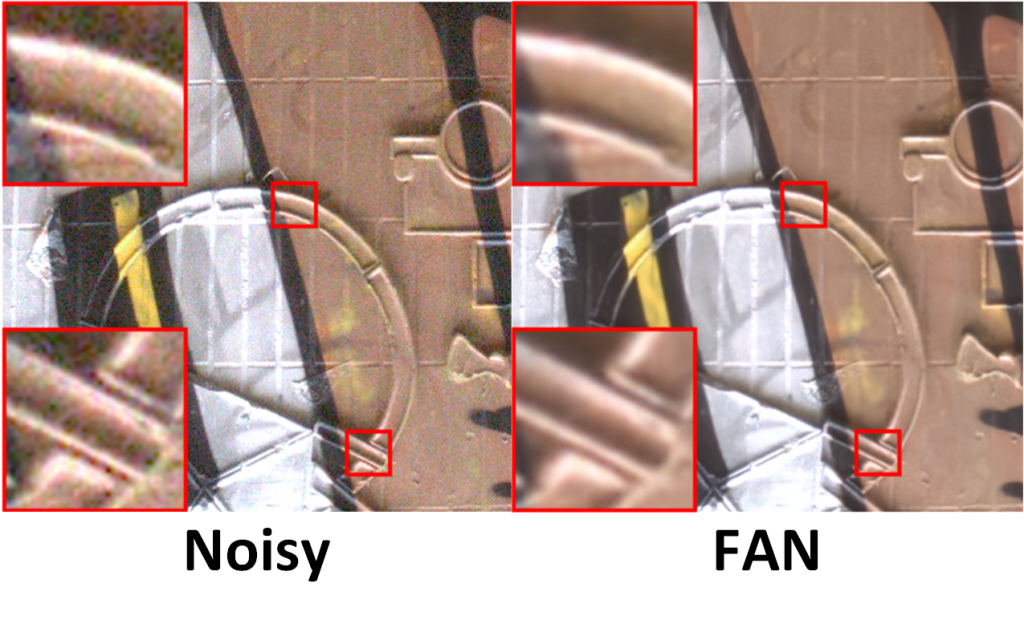
Claim: The FAN (Frequency Attention Network) is proposed for blind real noise removal exploiting spectral information and structural information of images and employing the attention mechanism to enhance the feature maps. Abundant ablation experiments indicate that Haar wavelet basis function, which satisfies symmetry, orthogonality and compactly supported characteristics at the same time, can achieve the best performance on the proposed FAN model. Comprehensive evaluations on different noise distribution cases demonstrate the superiority and effectiveness of this model for image restoration tasks. Extensive experiments on the synthetic noise dataset and two real-world noise benchmarks indicate the superiority of the FAN model over other competing models at different noise type cases in blind image denoising. The proposed model can also be implemented on other low-level tasks including super-resolution and deblurring.

1 Comment